

Beyond standard Google Dataform: Smart templates to save BigQuery costs & Dev time
An extended all-in-one data modeling framework with Google Cloud Dataform

In today’s fast-moving world of analytics engineering, the tools you choose can make or break your project, both in terms of success and cost. While dbt has gained widespread popularity, as a Google Cloud user and a believer in keeping a minimum providers stack, I opted for Dataform, fully integrated into the BigQuery ecosystem and generally available since 2023.

From legacy queries to Dataform models
Between mid-2024 and early-2025 at GOZEM, my team and I migrated all our legacy scheduled queries into Dataform models. The improvements were immediate:
Better dependency management, especially in models execution hierarchy.
More maintainable modeling patterns.
A stronger and more scalable foundation for our data transformations, with dependency integrity, CI/CD integration, and modular modeling that grows with our data volume.
It was a major step forward, but also the beginning of new challenges.

The limits of the basic implementation
Even though Dataform was a huge relief for our SQL pipelines, some pain points soon became apparent:
Full-table assertions on large datasets. Most of the time we only needed to validate recently updated or created partitions, but the built-in model assertions scan the entire table; an unnecessary cost hit.
Partition-aware merges. BigQuery MERGE statements only support explicit partition filters in the ON clause. Dataform doesn’t automatically detect or fetch partitions from source data. While updatePartitionFilter reduced unnecessary scans, it couldn’t dynamically handle composed filters or subqueries due to BigQuery’s constraints.
Schema evolution headaches. Before version 3.0.3 introduced the onSchemaChange property in early 2025, every new column in a source table had to be manually added to the target. That meant extra dev time and more room for human error.
The trade-offs before the light
At that point, we survived through workarounds; long pre_operations blocks in some models, and even external Python scripts orchestrated in Airflow to prepare partition variables and handle schema quirks. They worked, but came at a cost: more development time, more complexity, and higher maintenance.
Our goal was simple: solve all of this directly in Dataform, and make it automatic.
In the sections below, I’ll explain how we extended basic Dataform into an advanced framework that could:
Reduce repetitive model code.
Cut assertion costs by scanning only updated partitions.
Handle schema changes intelligently and safely.
Remove external orchestration dependencies.
All while staying 100% native to BigQuery.

The power of Dataform templating
We realized what we needed was full control over incremental model execution flow. Dataform’s operations models offered flexibility, but rewriting the same logic in every model wasn’t practical. So we built our own custom template, leveraging Dataform’s includes mechanism for repository-wide code reuse (functions, constants, and shared helpers).
That meant coding in JavaScript — a programming language I wasn’t fully comfortable with at first — and even rewriting parts of Dataform’s built-in logic to fit our workflow.
If you know what you want, know how to debug, understand logic, and love learning while building… you can build incredible systems with (AI) coding agents.
Our smart incremental custom flow

Our template follows this flow:
Check if the target table exists.
1. If not, create it like a non-incremental full refresh from the model query output and stop.
2. If yes, create a staging table from the model query output.
2.1. Compare the staging columns to the target.
2.1.1. If new columns are found, alter the target to add them.
2.2. Extract distinct partition values from the staging table.
2.3. Build a merge query with the ON clause scanning only those partitions: ON staging.key = target.key AND target.partition_column IN (partition_values).
3. Execute the merge.
4. Create assertion views filtered on those same partition values.
5. Assert the views instead of the entire table.That’s it. Simple. Dynamic. Efficient.
The built-in updatePartitionFilter (eg: partitionColumn >= xPeriod) helped reduce merge costs, but it wasn’t flexible enough for our data changes. Our template dynamically identifies all updated partitions from the staging table and limits the merge to those areas only. This gives us fully refreshed data without manual runs, without external scripts, and without wasteful costs.
In addition to asserting only recently updated partitions, we have reduced more BigQuery costs and improved development speed — achieving smarter, faster, and fully native transformations.

Some additional nice-to-have features
Smarter ON clauses
Instead of relying on a dedicated transformed partition column, we directly integrate expressions like FUNCTION(target.partitionColumn) IN (partition_values) for greater simplicity and no additional column than needed, avoiding the target.FUNCTION error with updatePartitionFilter.

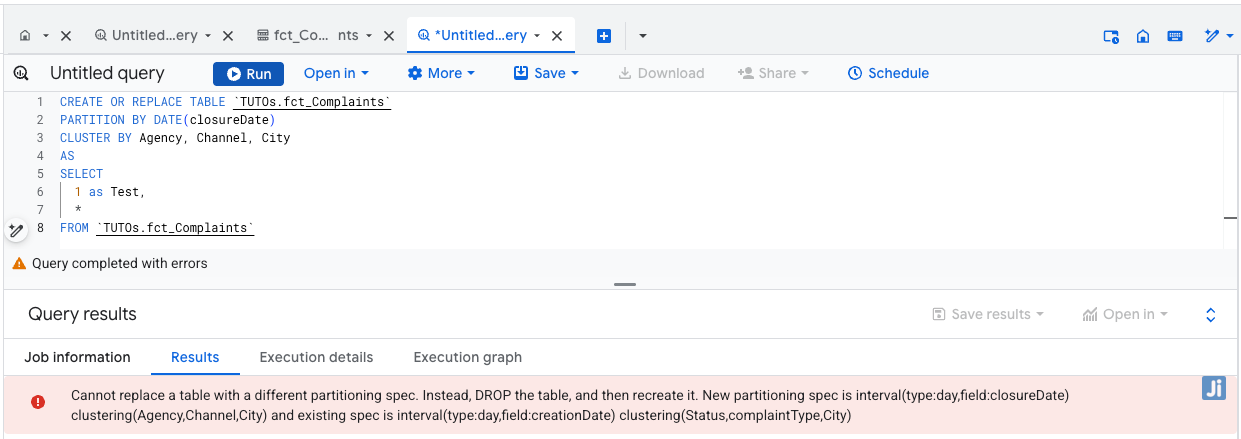
Advanced tables replacement
When partition or clustering columns change, BigQuery normally requires manual drops and recreations. Our framework automatically handles these updates.
Extended assertions
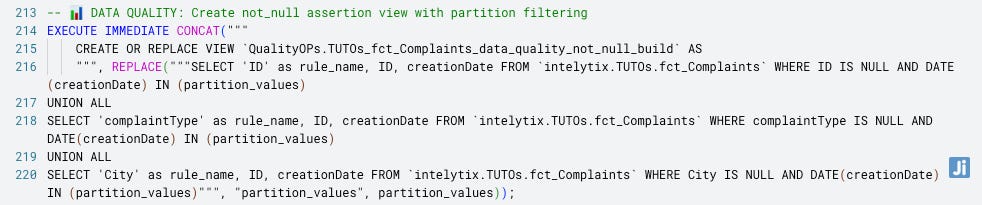
We went beyond the built-in data quality rules (uniqueKey, nonNull) to include checks like accepted_values, relationship, freshness, row_count, and percentage. Initially defined manually via rowConditions, they are now templated for faster and cleaner development.
Limited columns in assertions reports
Instead of using a wildcard in the assertions views, which shows all table columns when run, we add a property to specify only the columns we want to display in the assertions (views), reducing cost by leveraging BigQuery’s column-oriented capabilities.
We have significantly improved our SQL workflows using Dataform. With the right templates, it has everything needed to serve as a true all-in-one modeling engine within the BigQuery ecosystem. Our custom template showcased just how powerful Dataform’s operations models can be, and how much potential lies beyond the basics.
If you’re already using Dataform for advanced use cases, I’d love to learn from your experience.
You can explore the full template on GitHub: github.com/bolablg/gcp-dataform-modeling-lab. Although it is tailored to some specific needs now, I believe it can be extended to achieve more.